AI 기반 IT 취업 지원 웹 서비스 프로젝트
프로젝트 개요
- 프로젝트명 : AI 기반 IT 취업 지원 서비스 ( Github )
- 기간 : 2022.02 ~ 2022.04 (약 7주)
- 소속/고객사 : 팀 프로젝트
- 사용 기술 :
- 서버 : Flask, Tomcat, Spring
- 프로그래밍 언어 : Python, Java, HTML, CSS, JavaScript, JSP
- DBMS : MariaDB
- AI/NLP : GPT2, KoGPT2, BERT, Pandas, NumPy, TensorFlow, Scikit-learn
- 데이터 수집/크롤링 : BeautifulSoup, Selenium
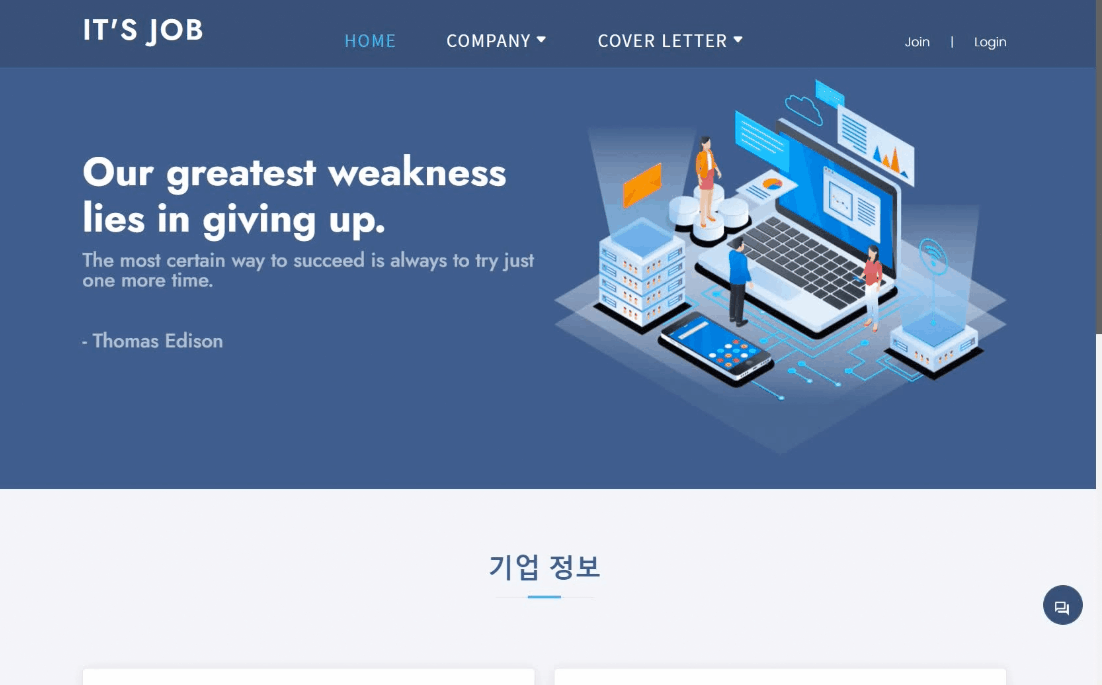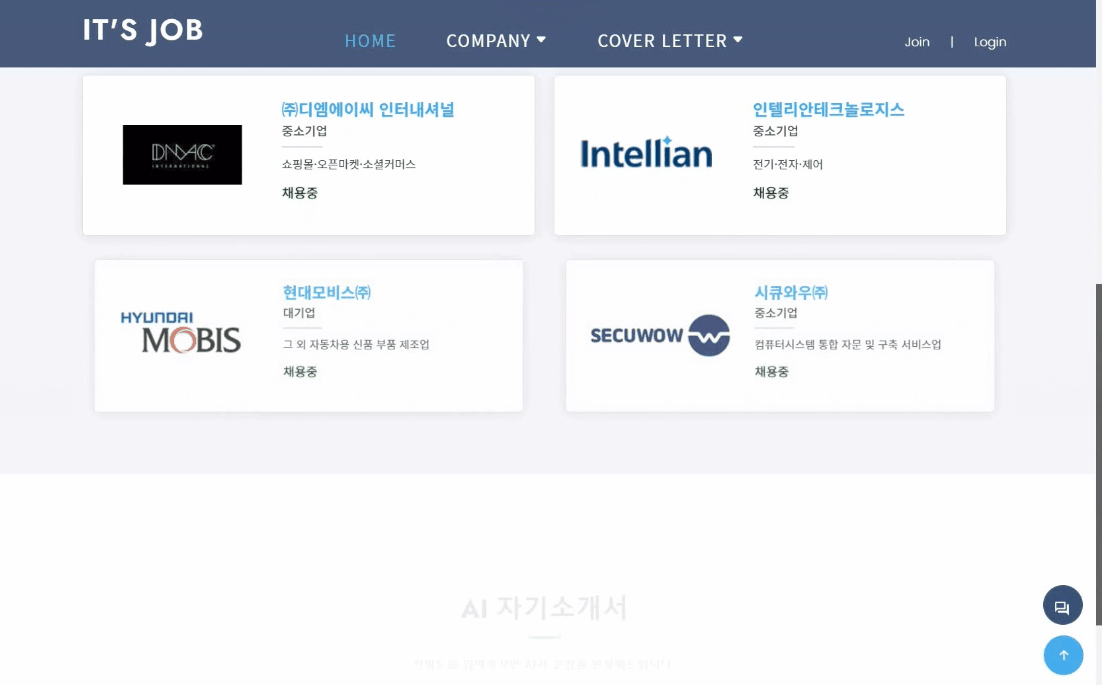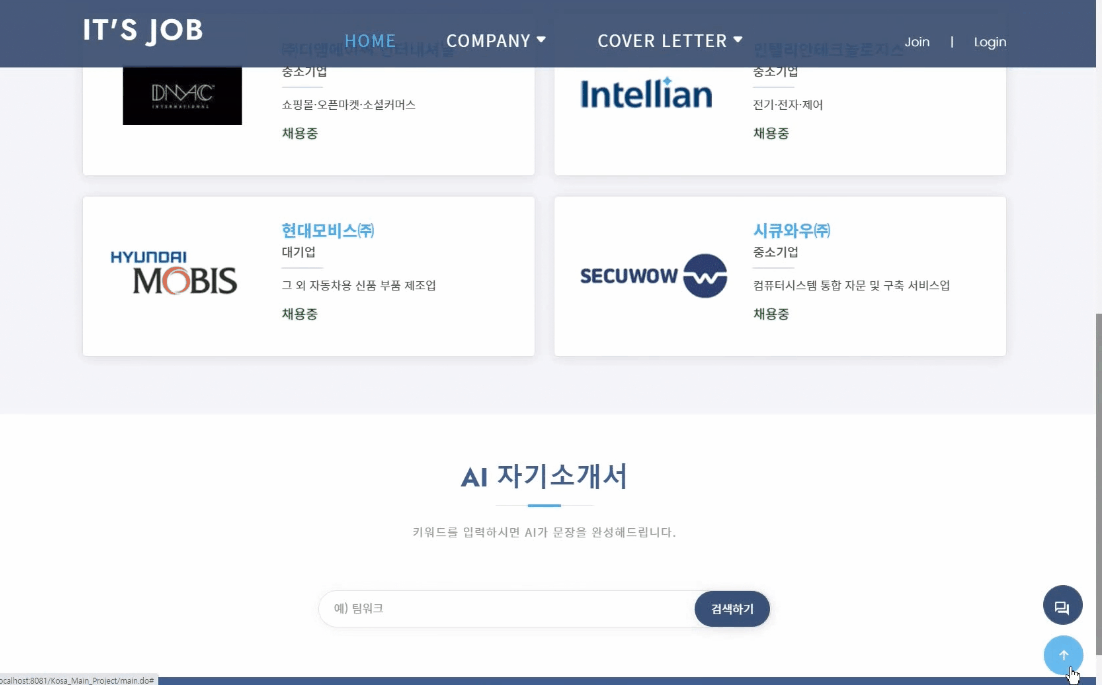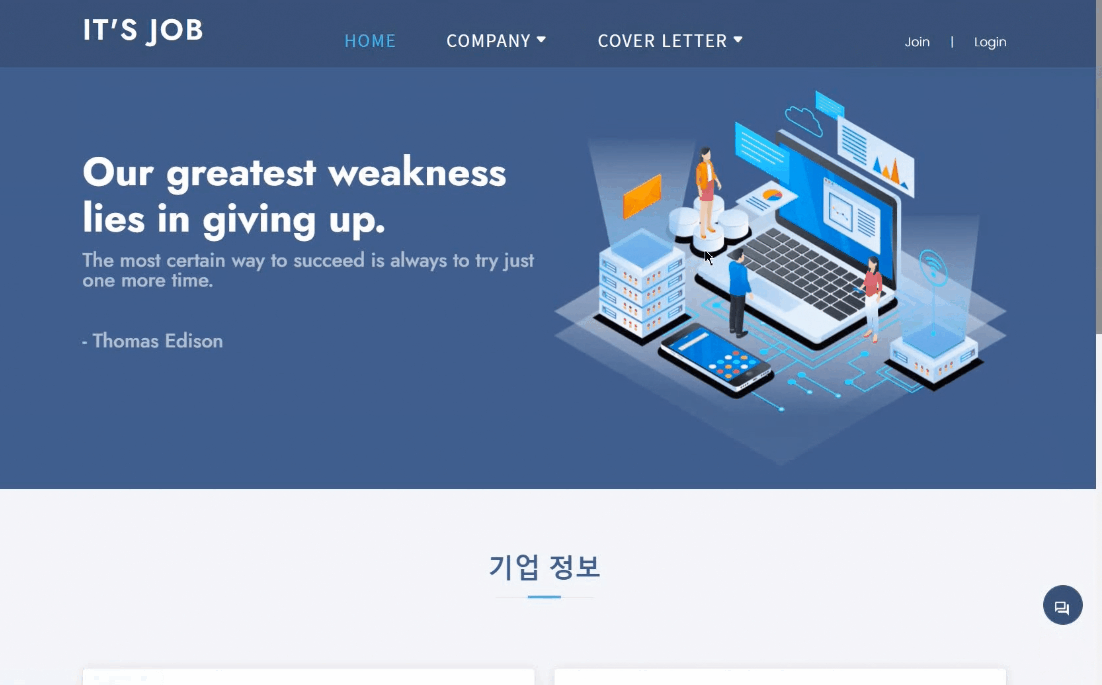
본 프로젝트는 취업 준비생을 위한 기업 추천, 자기소개서 작성 지원, 취업 상담 챗봇을 제공하는 웹 서비스입니다.
Spring 기반 웹 서비스와 Flask AI 서버를 연동하여 대규모 데이터 크롤링 및 AI 모델링을 통해 개인화된 취업 지원 플랫폼을 구현했습니다.
담당 역할
- PM : 데이터 수집, 전처리, DB설계, 서버 연동, 모델링 구현 총괄, 자소서 및 챗봇 기능 구현
- PL(본인) : Front-End구현, Spring 세팅, 유저 관련 페이지 구현, Git 형상 관리
- 팀원1 : 데이터 수집, 추천 알고리즘 구현, 기업, 채용공고 페이지 구현
- 팀원2 : 데이터 수집, 전처리, 자소서 모델 구현, Back-End 지원
데이터 모델링
1. 자기소개서 데이터 모델링
- 데이터 수집 : BeautifulSoup, Selenium으로 잡코리아 합격 자소서 크롤링 → 질문/답변 단위로 분류
- 전처리 : 첨삭 내용 제거, 특수문자 및 불필요 단어 제거
- 문장 분류 : 불필요 조사 제거 → 문장 벡터화 → 유사도 기반 클러스터링
- 모델링 :
- INTENT별로 분류된 데이터 학습
- 입력 문장을 DB 내 저장 문장과 비교 후 가장 유사한 답변 출력
- GPT2, KoGPT2 모델을 활용하여 자소서 문장 자동 생성
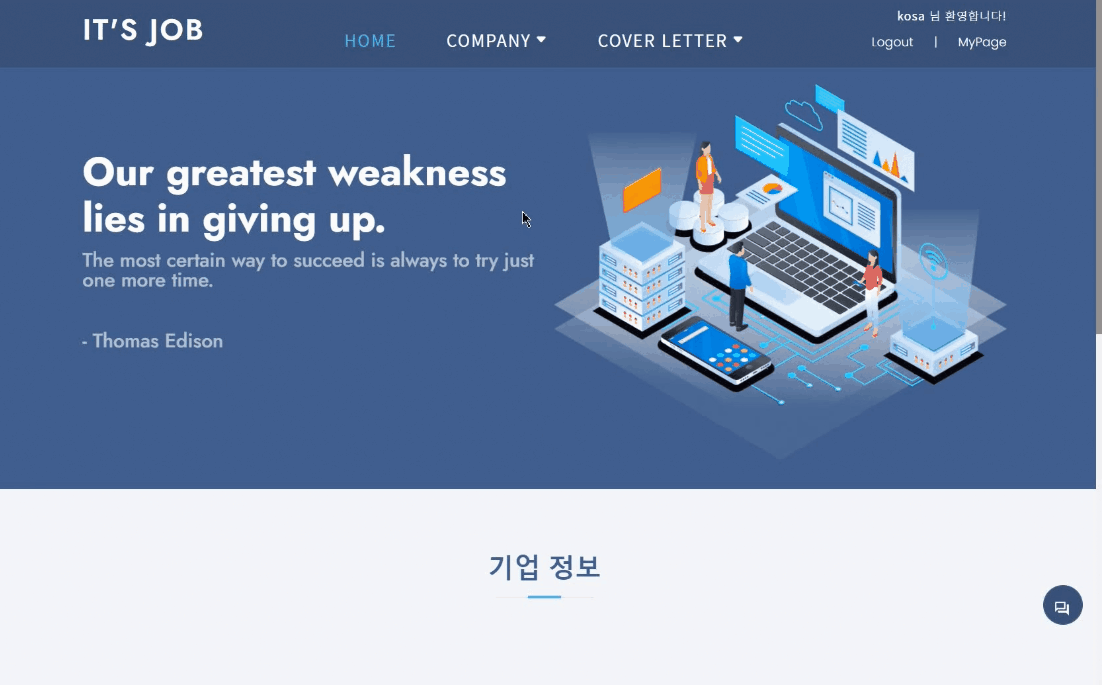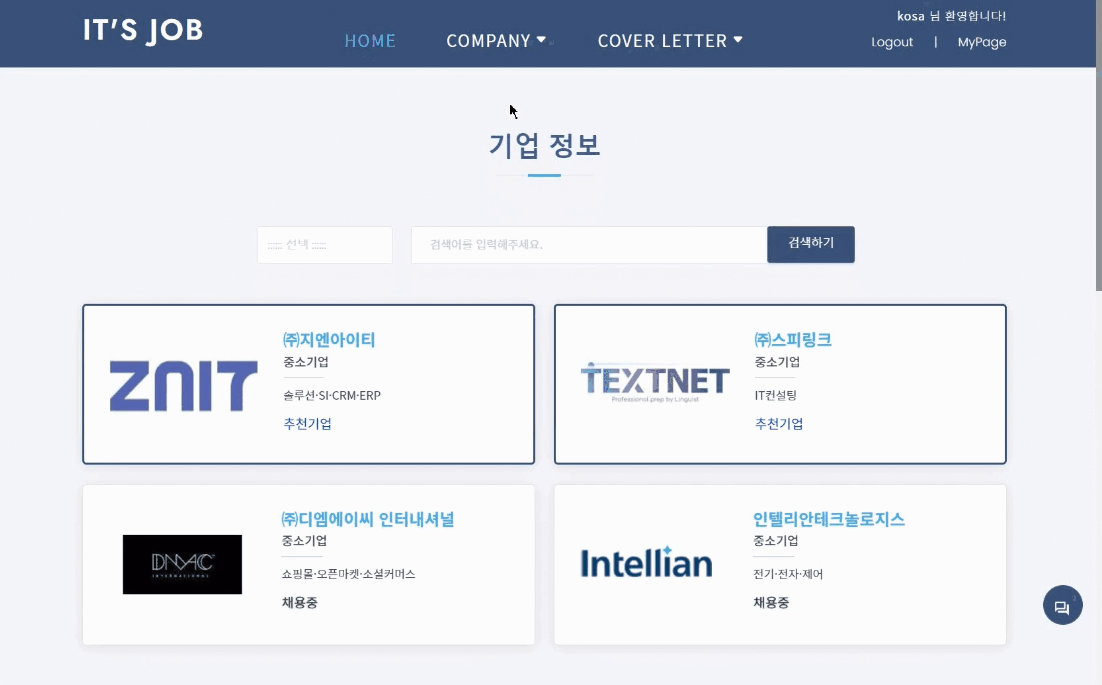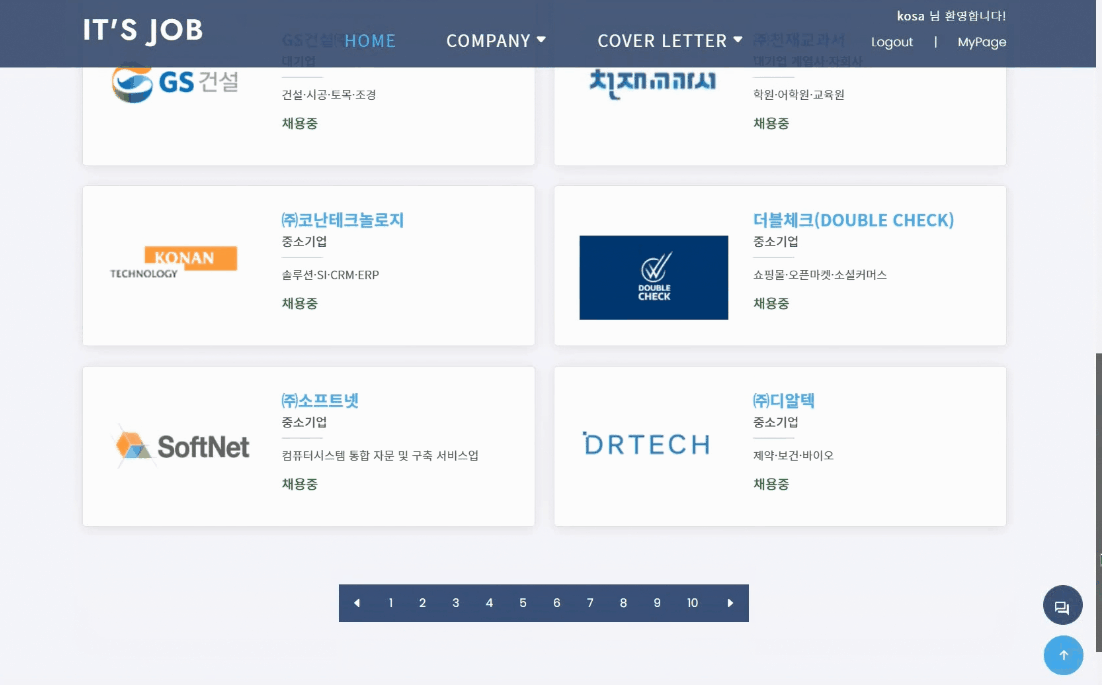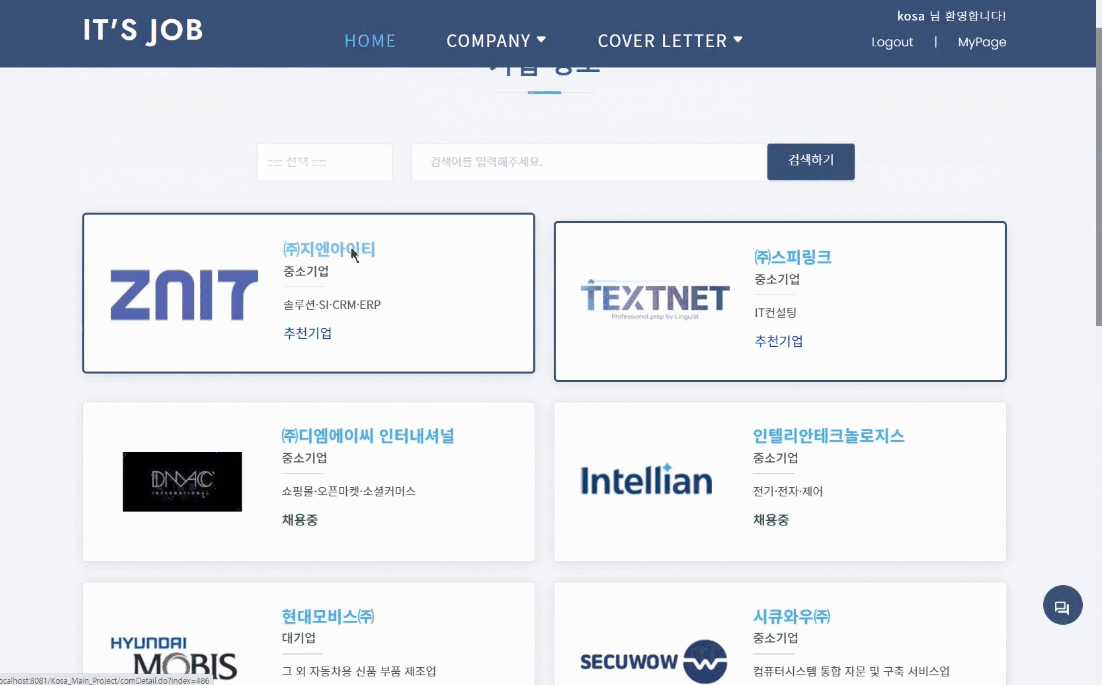
2. 기업 추천 데이터 모델링
- 데이터 수집 : BeautifulSoup, Selenium으로 잡코리아에서 기업 정보, 합격 스펙, 채용공고 크롤링
- 전처리 : 산업 분류 표기를 정규화(12개 카테고리), 특수문자 제거
- 추천 알고리즘 :
- 근사값 알고리즘 : 합격자 평균 스펙과 사용자 스펙의 절대값 차이 계산
- 콘텐츠 기반 필터링(Content-Based Filtering) + 원-핫 인코딩 : 사용자 스펙과 기업/채용공고를 비교해 유사 기업 추천
3. 챗봇 데이터 모델링(취업 상담)
- 데이터 수집 : OKKY 개발자 커뮤니티 질문/댓글 크롤링
- 문제점 : 취업과 무관한 글, 비방/욕설 포함
- 해결 : 취업 관련 키워드 포함 글만 추출, 추천수 마이너스 글 제거
- 전처리 : 댓글의 맞춤법·문체 문제 → PORORO 자연어 처리로 문법 교정 및 변환
- 임베딩 : 사용자 질문 ↔ 질문셋 데이터를 GOOGLE BERT 임베딩으로 벡터화
- 유사도 : 코사인 유사도로 두 벡터 간 유사도 계산 → 가장 가까운 답변 반환
4. 챗봇 데이터 모델링(기업 문의)
- 데이터 수집 : 잡플래닛 기업 리뷰(약 12만 건), 면접 후기(약 7만 건) 크롤링
- 전처리 :
- 기업명 표준화 (㈜ 제거, 영문 → 한글 통일)
- KOMORAN 형태소 분석 → 명사 추출
- 기업명을 사용자 사전에 추가하여 고유명사 인식 문제 해결
- 모델링 :
- Intent 분석 모델 : RNN 기반, 28만 건 데이터셋 학습
- 개체명 인식 모델 (NER) : 기업명에
B_COMPANY태그 적용 → LSTM 학습 - 질문·답변 매핑 : Intent + NER 결과를 바탕으로 DB에서 적절한 답변 검색